2016 年,我做过一次 AI 写代码创业
Jan 14, 2026Source: https://x.com/xleaps/status/2033027083476054377
2016 年,当 AI 还远没有成为今天这样的全民浪潮时,我已经开始认真尝试一件事:用语言模型来理解、修改和生成代码。
我给公司起名叫 ai.codes。这个名字几乎不需要解释:AI codes——把 code 当作动词,意思就是“AI 写代码”。
这个愿景在十年后的今天终于成为现实。“Agentic Coding”的浪潮已经席卷全球。只是当这一切真正到来时,我当年的那次创业,早已停在了 2016 年。
今天我想把这段往事写下来。它既是对那个技术爆发前夜的记录,也算是给 30 岁的自己留下一封迟到的回信。

当年的愿景
前史:我为什么会相信这件事
2011 到 2014 年,我在 Google 工作。那时我有个习惯:去看 Jeff Dean 最近又写了什么代码。
2013 年夏天,我注意到他在参与一个叫 DistBelief 的项目。那是 Google 早期的大规模分布式神经网络训练系统,本质上是在 CPU 集群上把神经网络的 forward 和 backward 过程做成分布式计算。虽然我当时并不知道 Jeff Dean 最终想把这条路带到哪里,但这件事成了一个契机:我开始花大量时间系统地学习神经网络。
2014 年,我离开 Google,搬到旧金山湾区,加入当时还不算显眼的 Fitbit。
因为此前已经对神经网络的能力有了比较深的认识,所以在 Fitbit 时,我主动把卷积神经网络引入到睡眠周期分类的问题里。Fitbit 是全球最早在可穿戴设备上做睡眠周期识别的公司之一,而我当时带的小组,应该也算是业界较早把卷积网络真正用到这一问题上的团队之一。那时主流方法仍然是特征工程加线性分类器,而我们在实践中很快发现,卷积神经网络的效果明显更好:它学到的信号表示,比人工构造出来的特征更强。
工作上我用的是卷积网络,但真正让我着迷的,其实是神经网络在自然语言处理上的潜力:翻译、理解文本,以及进一步地,理解程序。
我当时特别好奇:神经网络能不能写代码?尤其是那些我认为非常繁冗、复杂度并不高、模式却很多的代码。因为在工作里我常常看到,工程师尤其是做底层系统的工程师,很多时候不是在写配置,就是在写“生成配置的代码”。而与此同时,机器翻译已经开始取得真正的突破。既然 AI 可以做自然语言之间的翻译,那它为什么不能做自然语言到代码的翻译?更何况,很多代码在统计意义上比自然语言更规整、更低熵。
那时候我一直在博客上写《编程珠玑番外篇》,对各种编程语言的特性,以及人类编程过程中的种种困难,也算有不少思考。我逐渐意识到,在 AI 还远不完善的时候,真正可行的路径不是纯 AI,而是把 AI 和编译器技术谨慎地结合起来。
这些朴素的判断、长期积累的技术兴趣,以及对自己工程能力的信心,最终汇成了我创业的起点。
2016 年 8 月,我从 Fitbit 辞职,决定全职去做这件事。
那时候很多人注册的都是 .ai 域名。我偏偏反其道而行,注册了一个我至今仍然觉得很炸裂的域名:ai.codes。意思非常直接:AI 写代码。
第一版产品:从自动补全开始
语言模型和代码自动补全之间的联系,其实是非常直接的。所以我最早做的产品,就是一个更智能的代码自动补全工具,目标很简单:提高程序员在 IDE 里的工作效率。
为此,我下载了当时 GitHub 上大量的开源代码,专门搭了一套后端存储 and 训练架构,并在 GPU 上训练了一个在当时已经不算小的语言模型。它的任务和今天的大语言模型并没有本质区别:预测下一个 token。
2016 年时,Transformer 还没有出现;LSTM 仍然是最现实的序列模型选择。所以我的预测模型最终是一个 4 层 LSTM。现在回头看,它当然还很早期,但在当时已经足够让人震撼。
代码和自然语言相比有一个天然优势:它的下一个 token 往往受到更强的语法约束。比如前面没有出现左括号,后面就不应该凭空出现右括号。所以我当时很自然地加了一层约束:把那些在当前语法位置不可能出现的 token 过滤掉。
今天回头看,这和后来大家熟悉的 constrained decoding 属于相近思路;再往外推,也和后来模型生成合法 tool call、合法 JSON 时用到的约束式生成有共通之处。那时我并没有把它当成什么理论突破,只是觉得这件事太直观了,顺手就该这么做。
很快,我写出了一个 IntelliJ 插件,可以在编辑器里做代码补全。传统 IDE 的自动补全,通常只是帮你补一个函数名,比如你敲出 Array.,它在光标后面补一个候选方法;而我的系统,已经可以补全整段语句。
再往后,又把 Stack Overflow 上大量代码片段抓了下来,做了索引。我发明了一种三个斜线的注释方式:只要你输入一行三个斜线的注释,再回车,比如:
/// 此处我需要把文件内容读成一个列表
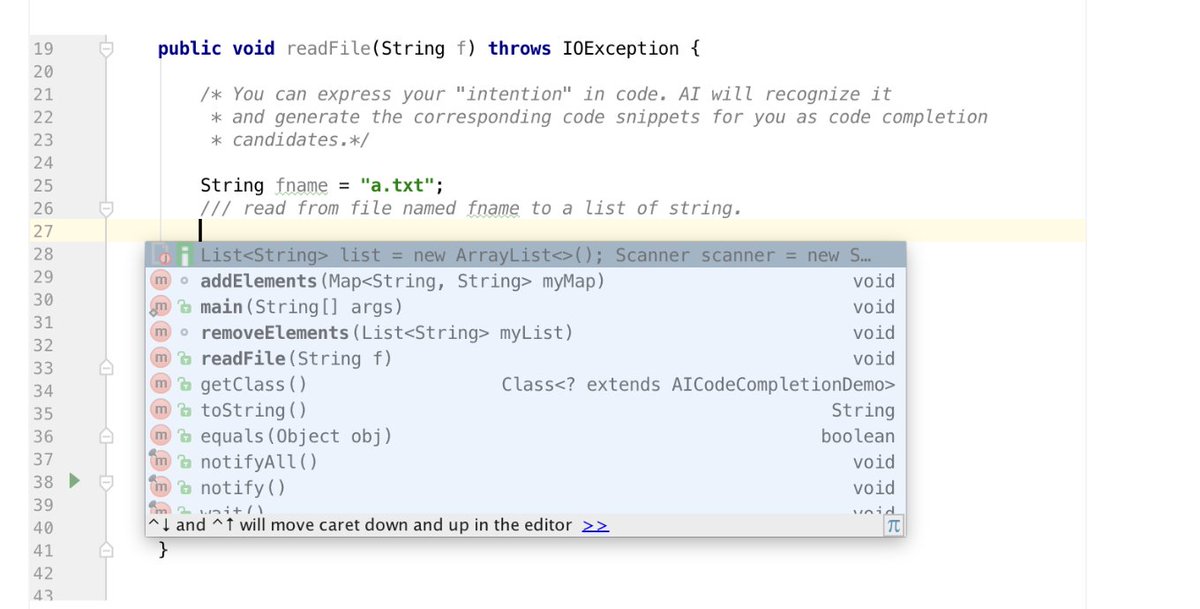
模型就会尝试把这句自然语言翻译成代码。
直到今天,我都记得第一次看到它真正“写代码”时那种近乎魔术般的感觉。其实背后的方法并不神秘:我先从索引里搜索,拿出许多候选代码片段,再让语言模型结合上下文继续生成。最后出来的程序不但语法正确,连变量名都能自动和上下文对齐。今天回头看,这已经很接近后来所谓 retrieval-augmented generation 的思路了。
在 2016 年,这样的效果是相当震撼的。
但我很快犯了一个巨大的错误:我不知道该怎么推广它,也不知道该怎么把它变成收入。
我当时相信,这样的技术只能卖给公司,而且需要结合公司内部代码库做定制化微调,才能真正体现魔力。于是我花了很长时间去向不同公司推销一个大家普遍看不懂、在没有定制化之前也看不出全部价值的东西。除了一些朋友和熟人愿意尝试,我始终没能获得真正的收入。
技术之外,更难的是人和时代
在硅谷,大家常开玩笑说,一家没有收入的公司往往估值最高。但当你做的是一件几乎没有足够多人能理解的事情时,融资会变得异常困难。
我记得有一次坐在一位投资人的办公室里,对面接待我的是一位几乎不了解 AI 技术的斯坦福 MBA。她问我的核心问题不是模型,不是产品,也不是程序员工作流,而是:这个技术能不能卖到中国去赚钱。
她甚至直接告诉我,如果系统还不能理解中文注释,他们就不会投,因为他们背后有中国资本的考虑。
这样的反馈让我很快意识到,问题并不只是我讲得不够好,而是很多人根本不在和我讨论同一个问题。我们嘴上说的都叫 AI,但脑子里想的并不是同一件事。
大多数硅谷投资人对这个方向的前景其实并不悲观,但它在当时实在太超前了,他们需要更多信号。而超前本身,恰恰就意味着缺乏信号。
九月份,我去山景城参加 Y Combinator 的面试。面试时,大家其实都挺喜欢我的产品,但最后的反馈仍然是:需要更多信号,鼓励我以后再来。

The rejection letter from YC
融资占据了我大量时间,也直接拖慢了产品和市场推进。直到那时我才真正意识到,没有一个合适的共同创始人,会把一家过于超前的创业公司拖入多么被动的处境。
我在 Google 时有一位非常尊敬的同事。我甚至飞回芝加哥很多次,试图说服他加入。但在他看来,这件事太异想天开。后来,我研究生时代的一位同事愿意承担这个风险,可整套技术栈既不是书本上能直接学到的东西,也不是他的博士方向,所以进展依然很慢。
回头看,我能理解这些同事和投资人。他们并不是错了,只是谁都不愿意为一个还没有被时代证明的愿景下注。
于是,那时的现实就是:我几乎一个人扛起了全部——技术、产品、融资、叙事、心理压力,还有生活本身。
那时候我的孩子才一岁多,刚学会走路,天天追着找我玩。我却整天在外面跑。到现在我还记得一个很具体的画面:有一天很晚回到家,妻子和儿子都已经睡着了,小猫蜷在旁边。我站在那里,心里知道自己隐约看见了一幅关于未来的拼图,可现实世界里却始终找不到把它拼出来的下一步。我不断碰壁。融资、合伙人、产品路径,所有未来都隔着一层雾。我父母只会说一句:你别太辛苦。
那种感觉不是简单的辛苦,而是一种更深的孤独:你知道自己看见了什么,但没有办法把它翻译成别人也能相信的语言。而与此同时,你又必须做点什么,才不算辜负那些仍然相信你的人。
创业是怎么结束的
被 YC 拒绝以后,我决定先把产品的不足想清楚。我又做了一些实验,训练了几个小模型,逐渐看清问题的核心:我缺的不是下一个插件,不是下一个 demo,也不是一份更漂亮的融资 PPT。
我真正缺的,是一个更强的模型。更直接一点说,是训练更大模型的钱。
我的模型表现仍然不够稳定,预测经常出问题。我已经把能想到的编译器技巧和语法检查手段都用上了,能补的地方几乎都补过了。剩下的问题,不是工程上的小修小补能解决的,而是模型本身还不够强。
到了圣诞节前后,我认真算过一次:我大概还需要 25 万美元, 以训练这个模型。
这个数字在我看来并不夸张,但在很多 VC 眼里却近乎离经叛道。融资的钱,在他们的想象里应该用来招人、做增长、讲故事,而不是被送进数据中心,最后变成 GPU 的热量。原本他们就不理解这个方向,到了这一步就更加无法理解:为什么我要为一个还不一定成功的模型,直接烧掉 25 万美元。
问题不在于他们是否尊重我,而在于我确实无法在“现有产品”和“如果模型能力跃迁后可能出现的产品”之间,搭出一条足够让他们相信的桥。
我需要钱,才能训练出更强的模型;但我也需要那个更强的模型,才能证明这件事值得投。
现在回头看,也许我还能想到别的路径。比如换一个切入点,先去找那些愿意容忍模型还不够聪明、但依然能从中受益的用户;或者更早围绕工具链、数据 and 工作流去搭一个可以慢慢生长的产品。但当时的我被这个死结困住了,觉得自己暂时推进不下去了。
于是我开始想,也许唯一的办法,是先把手上的技术能力变现,先去工作,等攒够了钱,再回来继续做这件事。
我记得那年圣诞节,经济压力已经非常真实了。我舍不得买圣诞树,直到平安夜前一天,才想起来要给儿子买一个玩具卡车。过完那个圣诞节以后,我终于承认:我不能再这样拧下去了。与其在原地内耗,不如先退一步,等时机成熟,再回来。
于是,我把下载 GitHub 代码后端的整套技术转让给了一家需要它的公司。然后我认定,自己接下来只会去两家公司赚点钱:OpenAI 和 Reddit。
当时拟定的三步走计划, 先做自动补全, 再做小规模填写, 最终达到只用自然语言
OpenAI 与 Reddit
那时候的 OpenAI 还只是一个很小的非营利组织,甚至还要先做一些题,才能拿到面试机会。那些题对我来说并不难。最终面试我的几位工程师中,其中一位是 Andrej Karpathy。
技术问题本身难不倒我。真正的问题在于,我太明确地知道自己想做什么:我想做自然语言处理,我想做 AI 写代码。而当时 OpenAI 的重心更多在强化学习 and 视觉上,我对那些方向并没有太大兴趣。
我记得他们问我,如果加入 OpenAI,我想做什么。我说,我可以做研究,也可以做工程,但我真正想做的,就是把 AI 写代码这件事做出来。
反过来说,这也意味着我未必是那个阶段的 OpenAI 最需要的人。现在回头看,我当时大概也算挺有性格。所以,收到拒信也并不奇怪。
第二家公司是 Reddit。
我当时的判断是:如果自然语言处理真的会成为未来的重要能力,那么 Reddit 这样的社区一定会变得越来越重要,因为全世界做 NLP 的公司,早晚都会需要 Reddit 这样的数据。后来事实也的确大体如此。
于是我加入了 Reddit,担任机器学习方向的高级总监。后来有朋友替我惋惜,觉得我当年如果去了 OpenAI,人生轨迹也许会完全不同。我倒没有这样想。人生不是一道能反复验算的题;很多选择,只能在当时那个版本的自己身上成立。
回头看,我错在哪里
我当然犯过不少错。
首先,我花了太多时间试图说服那些根本看不懂这件事的人。创业者需要讲故事,但不是所有人都值得你反复解释。对于一个过于超前的方向,更现实的做法往往不是说服所有人,而是尽快找到那极少数本来就能懂的人。
其次,我当时不敢 build in public。现在的创业环境已经很不一样了:公开写,公开做,公开迭代,本身就是积累势能的一部分。但那时的我没有这种心态,总想着等做得更完整、更漂亮一点再公开。结果就是,很多重要的工作做得无声息,并没有真正参与到后来那场波澜壮阔的历史中去。
最后,也是最重要的一点:我当时对自己的 failure mode 认识得还不够清楚。我没有足够清楚地知道,自己会以什么方式失败,会卡死在哪些约束上,以及当这些约束同时出现时,我应该怎样调整打法。比如我以为自己存了足够的钱,可以支撑一年的创业;但真走到关键节点时,我口袋里并没有 25 万美元让我豪赌。
回头看,我做对了什么
如果说我做对了什么,大概有两件事。
第一,我真的去做了一件疯狂的事。它没有成功,但它是真的:有代码,有模型,也有无数具体的记忆。它是我人生的一部分,而不是一个知识分子停留在脑子里的自我感动。
第二,我庆幸自己当时没有拿那笔投资人的钱。那是我拿到的第一份真正像样的投资合同,金额是 150 万美元,但合同条款我一点都不喜欢。拒绝那份合同之后,我可能得罪了半个硅谷投资圈,但我至今仍然喜欢当时那种“不愿受羁绊”的心态。我为此付出了代价,也因此保住了一点自由。
一件趣事,写给正处在 AI 浪潮中的焦虑者
最后讲一件小事。
2016 年夏天,我已经去了 Reddit,做的是推荐系统而不是语言模型,但我对 AI 写代码这个方向依然非常关注。那时候,硅谷做这件事的人彼此多少都知道一些。
有一天,两个俄罗斯年轻人找到我,想聊聊这个方向。他们一个叫 Illia Polosukhin,一个叫 Alexander Skidanov。
Illia 当时介绍自己在 Google TensorFlow 团队做技术带头人,Alexander 则是顶级 ACM ICPC 选手。我们在旧金山联合广场旁边的一家咖啡馆聊了一个下午。我跟他们讲了我做过的尝试、遇到的困难,也把自己接触过的一些投资人和这个方向可能面临的挑战都分享给了他们。我甚至很坦率地提到,有一位对这个方向很热心、但我并不喜欢的投资人;只是那个人当时已经开始转向区块链,我也不确定他是否还会投代码方向。
他们也告诉我,他们想做的事情是:用 AI 去生成 ACM 编程竞赛题目的代码解答。而且我能感觉到,他们手里或许有比我更强的方法。
分开的时候,我真心祝愿他们,也想,这两个人也许真的能做成点什么,我得继续关注一下。
一个月后,他们从那位投资人手里拿到了一笔融资,公司名叫 near.ai,意思是 AI 离我们已经很近了。
但接下来事情的发展,和我当时脑中那条线性的技术演进路径几乎完全不同。几个月后,公司转去做 AI 生成 dApp;再过几个月,又转成了做公链;最后彻底变成了一家区块链公司。
我为什么讲这个故事?
因为熟悉大语言模型历史的人大概已经知道了:Illia Polosukhin 实际上是 Transformer 论文《Attention Is All You Need》的作者之一, 当时这个划时代的论文刚刚发表, 但没人能看清楚它的意义。今天的 ChatGPT,以及整个现代大语言模型时代,几乎都建立在 Transformer 这项工作之上。
这件轶事最让我感慨的地方在于:我们这些身处其中的人,其实一直都被未来的迷雾包围着。所谓“看对了方向”或者“看错了方向”,很多时候并不足以决定你最后会走到哪里。你也许看见了未来,却没有资源;你也许拥有资源,却走向了别的方向;你也许参与了最关键的基础工作,却仍然不知道它会在几年后如何改变世界。
未来并不是线性展开的。
所以,焦虑并不能真正帮助我们接近未来。更重要的是,在你当下所能看到的边界之内,做一个对得起自己的选择;至于剩下的部分,就交给时间。