TopLanguage 论坛上有人问为啥信息论要使用 \(H = -K \sum_{x \in X} p(x)\log p(x)\) 的形式. 或者说, 为啥要用不直观的对数.
古典的解释很简单, 对于一个有 \(N\) 种状态的事件, \(p\) 进制编码的时候, 需要的位数是 \(\log\_p N\). 也就是 \(– \log\_p (1/N)\).
这种古典方法有很多局限. 最显著的就是 \(N, p\) 必须是整数. 熵的概念既不能推广到一般概率, 也不能推广到一般的对数为底.
下面我介绍两个公理化的定义. 一个是 Shannon 的原始定义, 一个是我偶然想到的模仿 Kolmogroov 概率公理化定义一样, 关于自信息量的定义.
Shannon 在 A mathematical theory of communication 的公理化定义被很多人忽略了. 我简单的归纳一下.
- 信源可以看成是一个 Markov 过程. 现在相信大家都知道这一点了, 比如抛硬币, 就是这样的图:
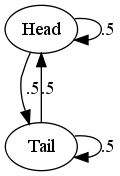
这里, 信源的熵(不确定度量)只和均衡状态下各态的到达概率有关. 而和其他量无关. 也就是说, 迥然不一样的Markov过程只要稳定状态下各态概率一样, 不确定度量也一样. 这样, 信源就抽象成了和具体工作机理无关的 Markov 信号发生器. 这个是信息论的关键前提.
-
假设离散事件发生的概率为 \(p\_1, p\_2, \ldots, p\_k\). 其所含的”不确定度量” \(H\) 是关于 \(p\_i\) 的一个连续函数.
-
假设 \(p_i = \frac{1}{n}\). 则 \(H\) 关于 \(n\) 是增函数. 因为 \(n\) 变大, 表示可选择的更加多, 也表示“不确定度量”在增加.
-
如果随机变量 \(X\) 的概率分布依赖于 随机变量 \(Y\) 的分布, 那么\(X\) 的熵 \(H(X)\) 可以表示为 $$ H(X) = \sum_{y \in Y} p(y) H(X y) $$
从这三个公理出发, Shannon 证明, \(H = -K \sum_{x \in X} p(x) \log p(x)\) 是唯一可能的信息熵的表示. 具体的证明也不难. 从因为从 3 出发可以简单推出.
假设 \(H(\frac{1}{n}, \ldots, \frac{1}{n}) = A(n)\)
则有, \(A(t^{n}) = n A(t)\). 按照连续函数的性质, 解一下函数方程, 可以得到 \(A(t) = K \log t\).
我想到的公理化定义说起来也比较简单, 是依赖于自信息量的公理化定义. 基于和香农同样的假设, 一个事件的自信息量 S(X) 定义为该事件概率分布的一个连续函数.类比于 Kolmogorov 建立的概率公理体系, 自信息量是概率度量空间上的一个实度量, 满足一下几条公理:
-
非负性. 对于任何事件 \(X\), \(S(X) \ge 0\)
-
信息量的可列可加性. 即在条件概率的意义下, 以两项为例, 有,
直观的解释是, 事件 \(X\) 与事件 \(Y\) 联合提供的信息量, 等于知道 \(X\) 的信息量加上知道 \(X\) 后 \(Y\) 提供的信息量.
根据公理2, 很简单可以得出独立同分布事件 \(X\), \(Y\) 联合信息量 \(S(X, Y) = S(Y) + S(X)\). 根据这个可以推导出两个结论, 一是概率为 1 的事件的信息量必然为 0. 二是因为独立分布事件的概率是两个概率相乘. 令 \(t\_x = p(X), t\_Y = p(Y)\), 则有 \(f(t\_x * t\_y) = f(t\_x) + f(t\_y)\), 此函数方程的解为 \(k \log t\). 其中 \(t\) 是概率, \(\alpha\) 是任意常数. 根据1 可知, \(\alpha\) 必须取负数. 因此, 令 \(k = – \alpha\), 得自信息量公式 \(– K \log p\). 与古典结果一致.
在自信息量的定义之上, 熵就是很显然的了. 事实上, 熵就是系统各状态自信息量的数学期望, 即:
\[H = -K \sum_{x \in X} p(x) \log p(x)\]公理化定义的好处是, 整个信息论建立在了现代数学的磐石之上, 并且能与其他数学领域相结合. 信息论诞生以后, 到最近, 都一直受到数学家的重视. 在关于下一代移动通讯网络 (4G)* 的研究中, 非常纯数学非常抽象的代数数论和代数几何, 居然和信息论相结合, 产生了令人惊讶的代数几何码, MIMO 空时码等先进的编码技术. 编码理论和代数结构相结合, 不光在实际上产生了效果好的应用, 而且在理论上也出人意料, 建立了不同学科之间的深刻联系. 信息论早就已经超出了一个工程分支的范畴, 成了非常新, 非常有活力的一个数学练兵场. 有兴趣致力这方面研究的可以阅读几篇 IEEE Transaction on IT 上面的一些经典文章.
延伸材料:
-
A Mathematical Theory of Communication by Claude E. Shannon (http://cm.bell-labs.com/cm/ms/what/shannonday/paper.html)
-
Wikipedia Article: “Entropy in thermodynamics and information theory” (http://en.wikipedia.org/wiki/Entropy_in_thermodynamics_and_information_theory)
- 3G (第三代移动通信) 的编码, 据我有限的知识, 一般是基于 Turbo 码这样一个随机的编码方式. 关于这个编码有一段非常有趣且有启示的故事: http://jcst.ict.ac.cn/downloads/xsqy/qy1503.pdf