Out of the box
May 26, 2007来美国常常听到一个词组叫做 out of the box. 这个词有两个不相关的意思,
第一种是和 think 搭配, 叫做: think out of the box. 大致的意思就是要用非传统的创新的思维方式去思考问题. 这个词组出处比较好玩, 就是小时候大家做过一个智力题, 九个点排成 3*3 的方阵, 要用一根最多折三次的线把九个点全盖住.

一般人就想来想去, 被这九个点形成的一个无形的”盒子”限制了, 线走不出出这个盒子. 所以思来想去还是不得其解, 其实这个盒子是隐形的. 下面就是一个解, 只要线一出盒子, 豁然开朗. 而现实中, 人的思维往往就被隐形的盒子制约了.
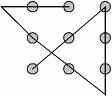
在李开复先生的 <做最好的自己> 这本书中, 也举了这个例子; 书中说, 甚至, 如果思维更加发散一点, 不限制线的宽度, 一根线就可以搞定.
out of the box 的第二个意思类似于 off the shelf, 就是说这个事情拆开盒子就能用了, 不需要装额外的软件, 硬件啥的. 比如说, 在Linux上很多专业刻录软件通常都是随发行版发布的. 这些就是 out of the box 的功能.
最后说个好玩的. 原本 in the box 和 out of the box 是相反意思的两个词组, 但是最近已经不能说 in the box 了, 因为 SNL 去年圣诞节出了一个 MTV, 题目叫 dick in the box. 内容有点搞笑且少儿不宜, 因此, 现在只要一说 in the box, 大家就想到这个 MTV, 因此没人说 in the box 了. 也是潮流文化影响下的语言的一种变化, 就像同志, 小姐这个词被糟蹋了一个意思.
